Hi! I'm Kaila Gilbert — a technologist, data scientist, and multi-genre writer who believes wholeheartedly in the power of people. Whether I'm analyzing our current world or dreaming up brighter ones, I bring curiosity, depth, and analytical expertise to all that I do.
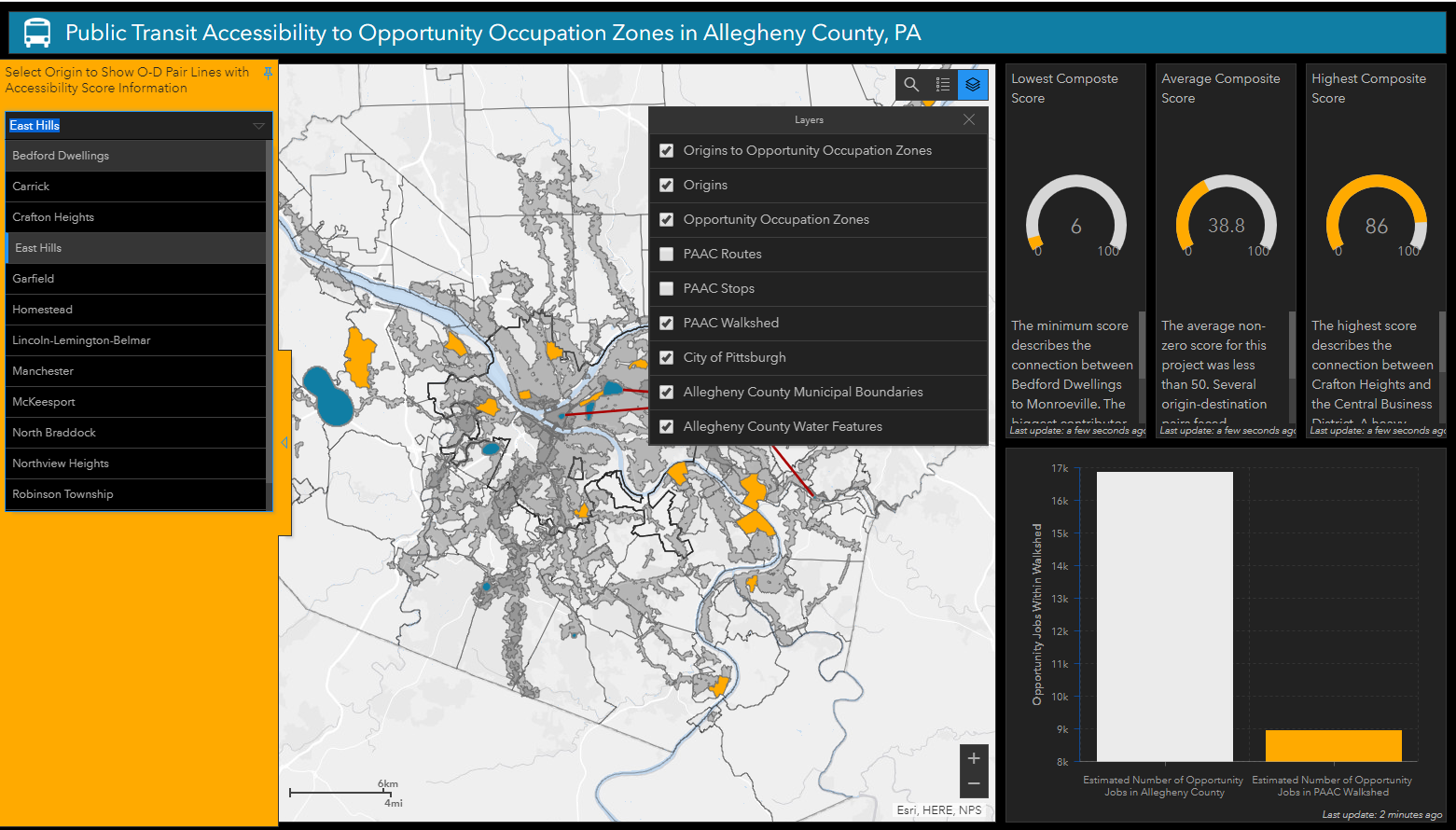
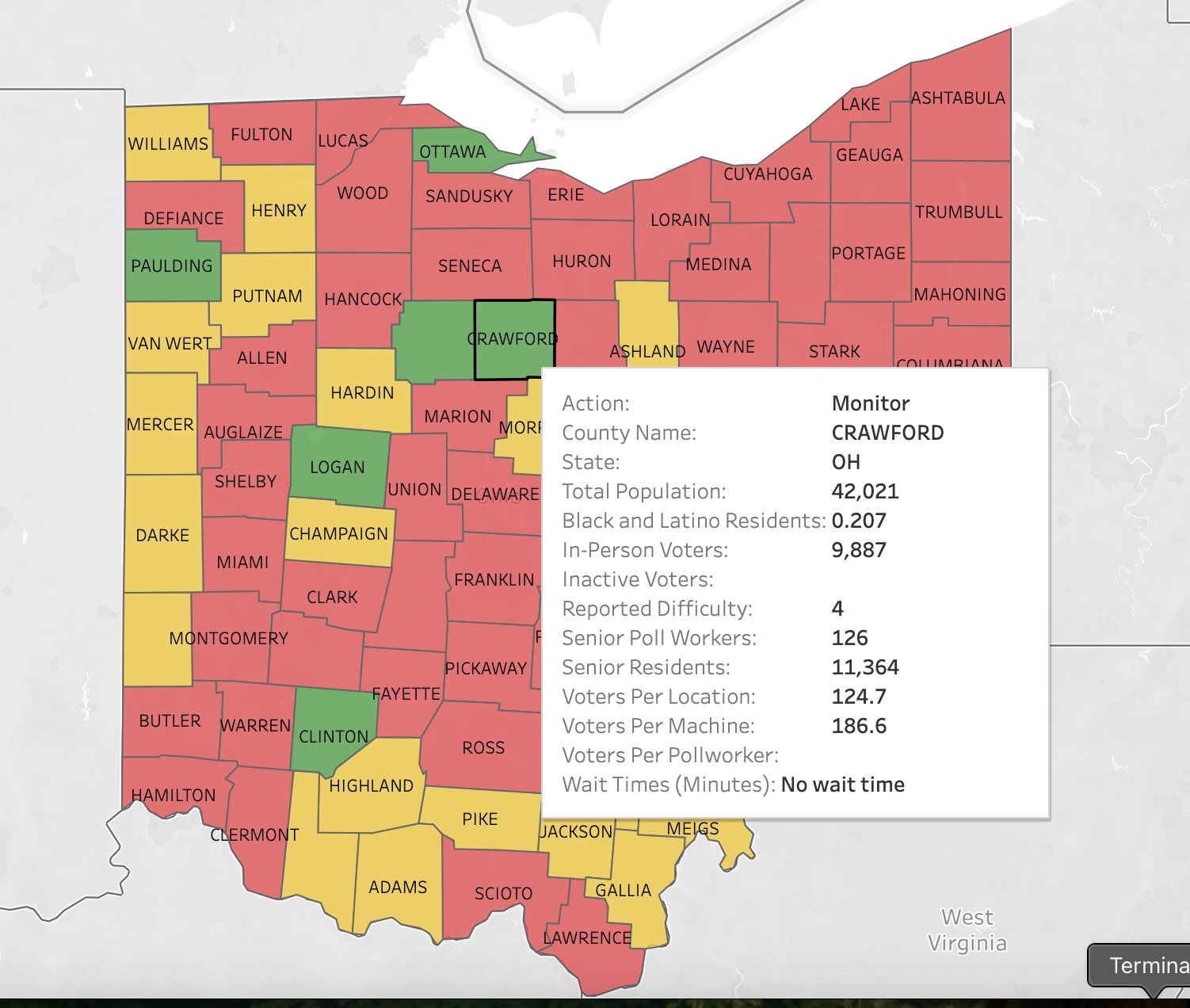
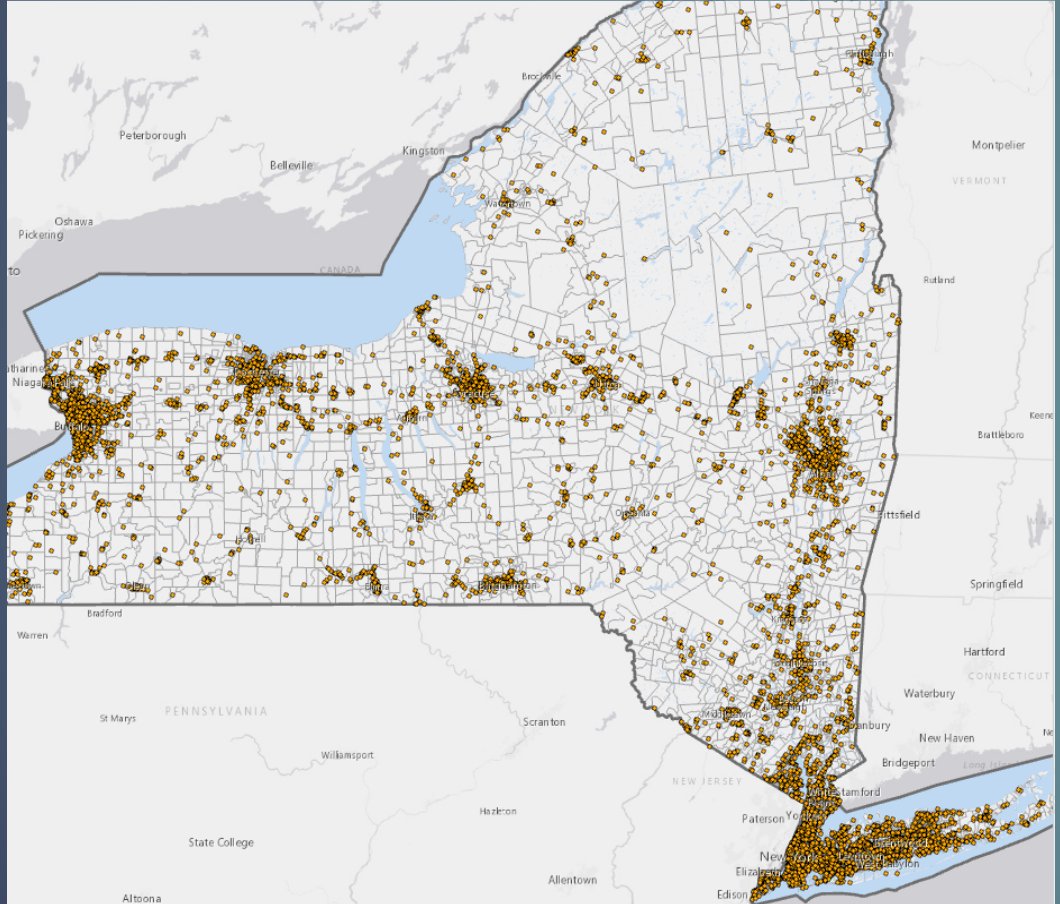
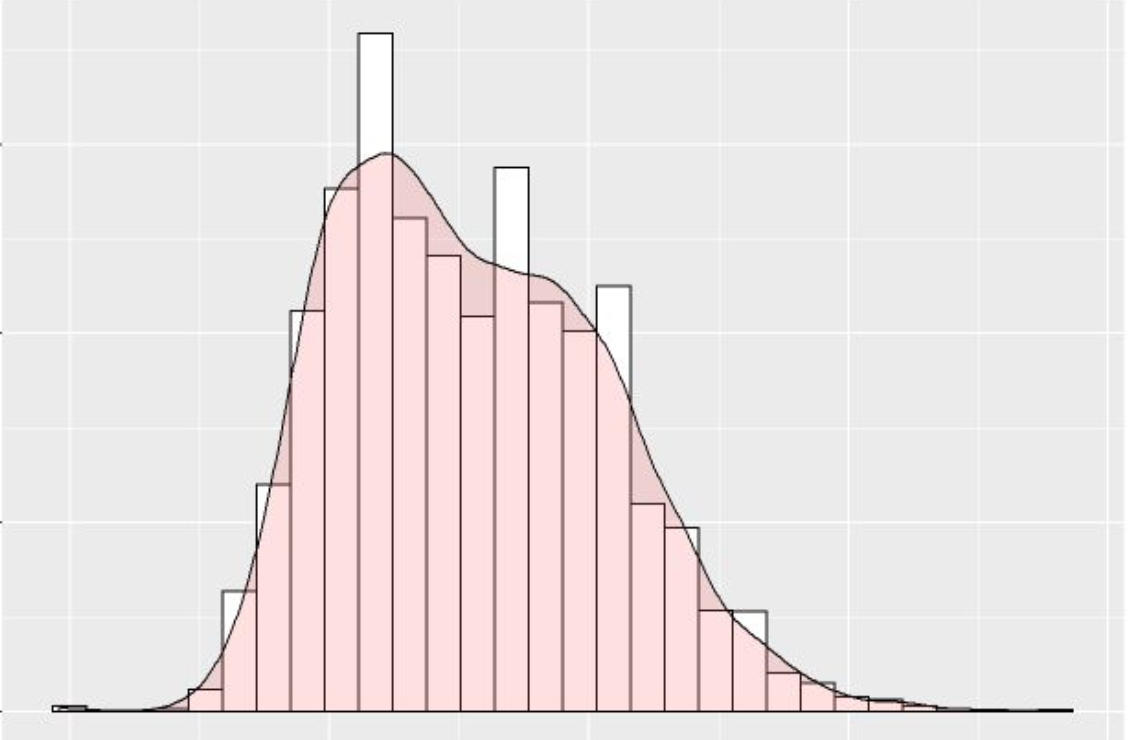
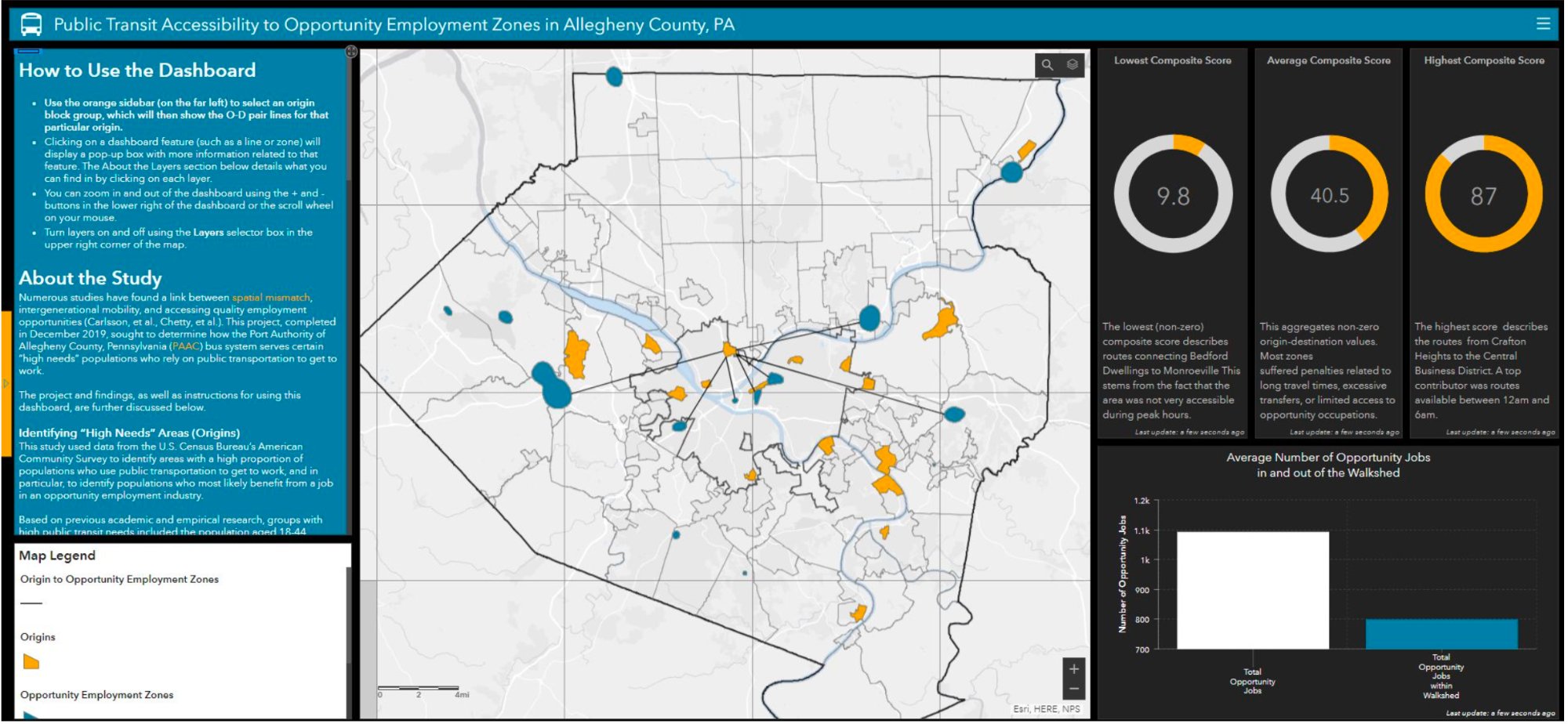
As a graduate student in Data Science, I cultivated a deep love for data mining and the craft of visualization — the idea that a well-told story with engaging visuals can communicate what a thousand rows of data cannot. I was honored to spend five years at IBM, bringing the cutting-edge of AI and data analytics to Federal clients and civilian institutions. Before IBM, I gained experience with startups, nonprofits, and Fortune 50 companies.
My graduate work spanned geospatial analysis, AI/ML, statistical modeling, and policy studies. I also hold a B.S. in Human and Organizational Development, a foundation that puts people and strategy at the heart of all I do. Outside of work, you'll find me reading, travelling, playing D&D, and applying my technical skills to delicious recipes.
I'm currently open to part-time and consulting opportunities in data science, analytics, and creative storytelling. If you have a dataset that needs to tell a story, let's make it happen.
Download Resume →